Context
At IDX (Intuit Data Exchange), my team owned the integrations that pull financial data from thousands of third-party providers — the data behind QuickBooks, TurboTax, and Credit Karma. It arrives two ways: APIs (~70–80% of traffic) and screen scraping (~20–30%).
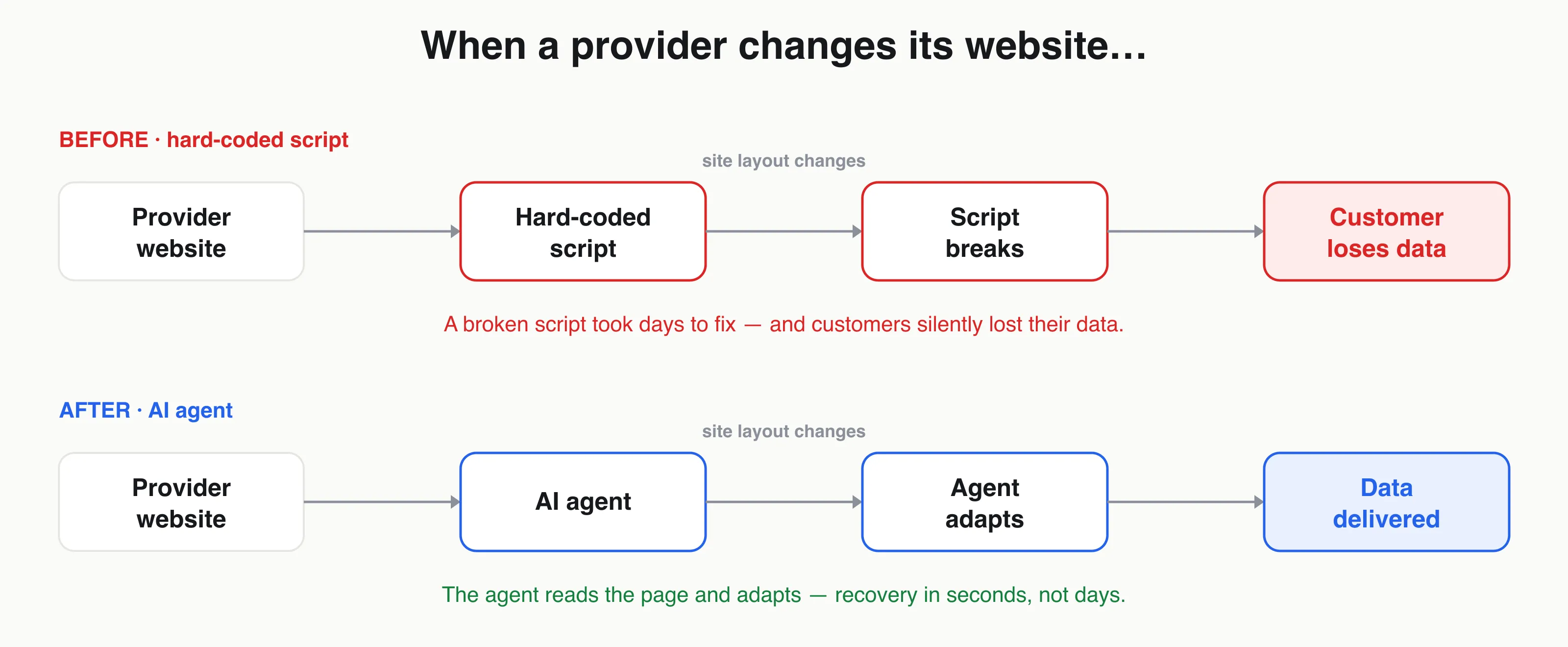
Scraping was the fragile path. Every scraper was a hard-coded script, and the smallest layout change broke it — silently cutting customers off from their data (no transactions to reconcile, no income history for a loan). Keeping the scripts alive was a costly, never-ending effort, and each fix took days.
The opportunity
Agentic AI had just become good enough to navigate a website like a person — reading the page, adapting to change, completing a goal. Tell an agent “download my bank statement” and let it figure out how. If it worked, fixes measured in days could become seconds. As product lead, I set out to prove whether it was real — and, if so, ship it.
Proving feasibility
I ran it feasibility-first:
- A proof of concept against a fake bank site — small enough to earn leadership’s green light for a full build.
- An eval foundation (the part I’m proudest of technically): on Intuit’s internal platform for agentic-AI development, I directed the build of 100+ mock provider cases, automated measurement of the agent against ground truth, and tracking of a full KPI suite — the foundation for all our agent evals.
- A clear bar for success, benchmarking the agent head-to-head against the existing scrapers. (KPI framework below.)
How it worked
A few technical decisions made it viable:
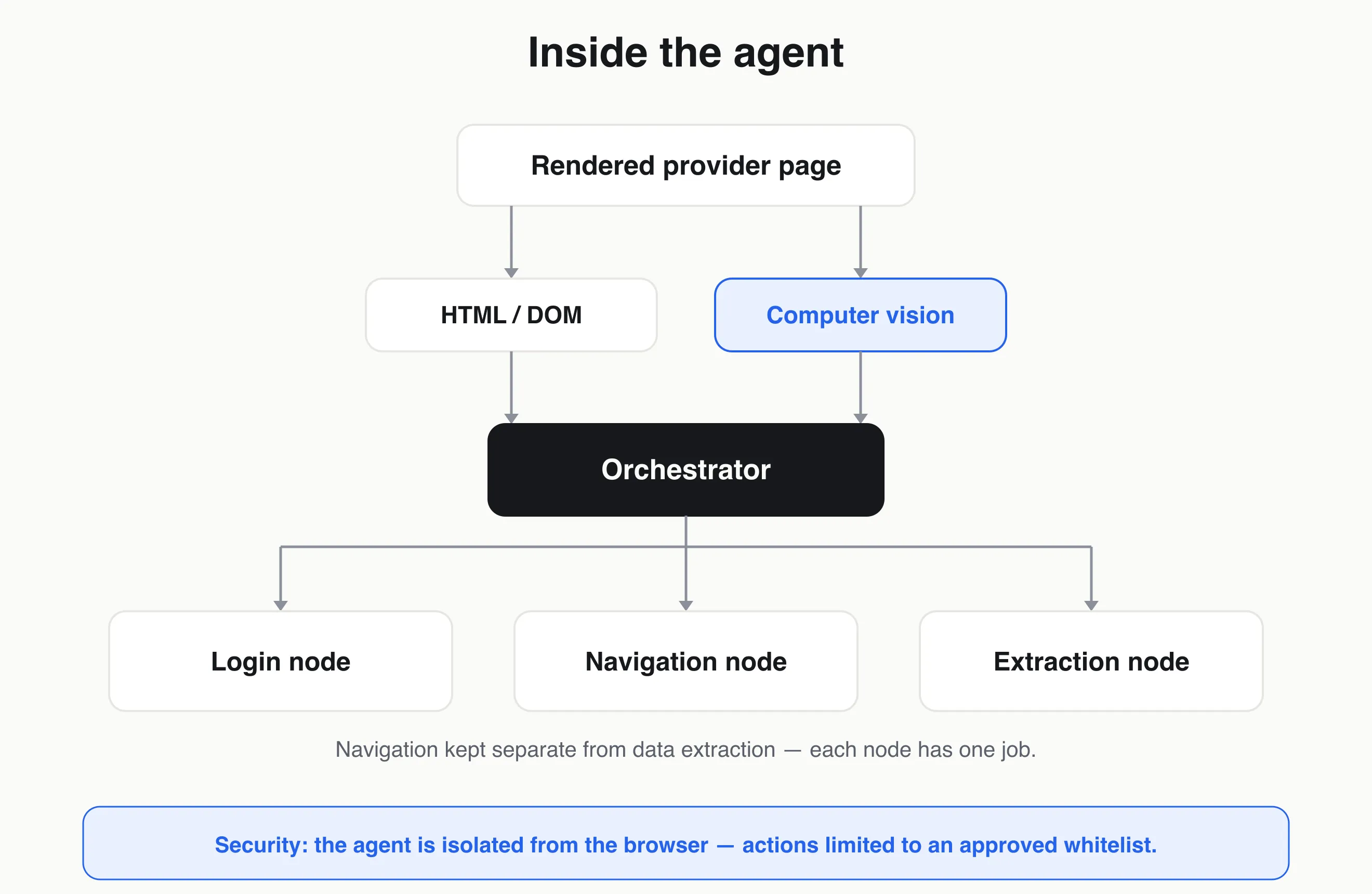
- A multi-node agent, not one mega-agent. An orchestrator coordinates specialized nodes — login, navigation, and extraction — and separating navigation from data extraction was essential to reliability.
- HTML + computer vision. The agent first reasoned over the page’s HTML/DOM; under my direction we added computer vision, which resolved a whole class of failures — like phantom elements that exist in the DOM but aren’t actually visible to a user.
- Safe by construction. In a regulated financial-data path, the agent is isolated from the browser and limited to an approved whitelist of actions, so it can’t do anything unintended.
From feasibility to production
The approach evolved as real-world constraints showed up (diagram below):
- Real-time autonomous agent — layout-agnostic and able to handle any site, but reasoning live on every run made it costly and slow: not scalable.
- Generated scrapers. We pivoted: a domain expert tags the page and the expected output, and the system generates scraper code that runs fast and cheap at runtime. This took us to production — a deliberately gated rollout of ~20 providers serving ~1,000 users — the first machine-generated agentic scrapers running in our data path.
- Human-in-the-loop, to scale. To go from tens of providers to hundreds, perfect code isn’t required — generated code plus a human fix, paired with a customer-facing capture tool that records the hardest, slowest stage (new-provider onboarding, MFA) for an engineer or AI to finalize.
Throughout, safety stayed front of mind — including ensuring generated code never mishandles sensitive data (e.g., leaking a customer’s SSN into a log).
Results
- First machine-generated agentic scrapers in production in IDX’s regulated data path — a careful, gated rollout of ~20 providers / ~1,000 users.
- Fix/recovery time: days → seconds.
- ~95% extraction accuracy in benchmarking.
- An eval framework and architecture that made it safe to put AI directly in the data path.
- A business case framing the approach as a ~$10M annual savings opportunity.
What I learned
Feasibility is a product question, not just a technical one. The real work was building the evals, the safety model, and the rollout gates that let a regulated organization say yes to AI in the data path — then re-scoping the strategy (autonomous → generated → human-in-the-loop) as cost, latency, and scale realities emerged. The biggest lever was aiming the technology at the longest, most painful stage of the pipeline.