Context
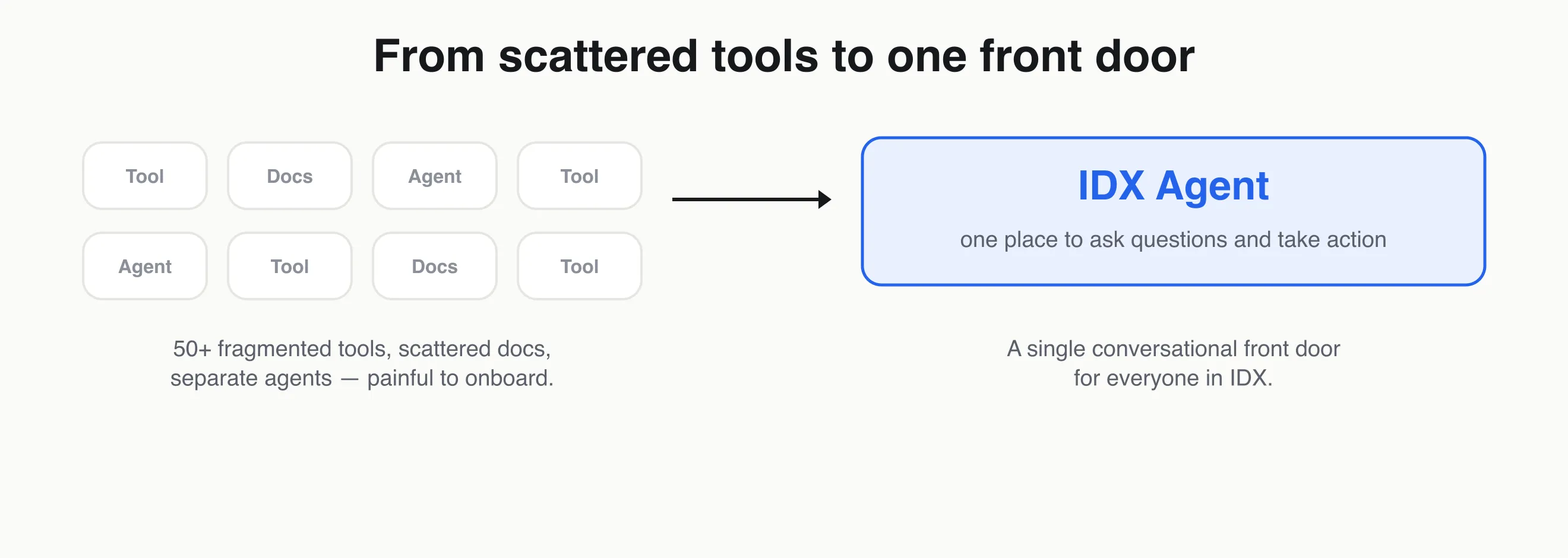
IDX is a sprawling internal world: dozens of services and over 50 different tools, each with its own docs, APIs, and tribal knowledge. Two things made that painful:
- Onboarding was slow. We relied heavily on short-term contractors, and getting someone productive across so many tools took weeks.
- Even veterans got lost. Hopping between tools meant re-learning context every time.
And it was getting worse: teams were each building their own agents with their own UIs, so the AI experience was fragmenting too.
The vision
One conversational front door for everyone in IDX — engineers, support, ops — where you can ask a question, find a service, or take an action (check an integration’s status, fix a script, kick off a build) without knowing which of dozens of tools to open. I led product for this: the IDX Agent, the AI layer of our unified platform, IDX Studio.
How it worked
(Architecture below.)
- A knowledge base that stays current. A job runs across 300+ repositories, indexing only what changed — the deltas — and feeds it into a RAG layer. That indexing is what makes retrieval fast and answers up to date: the difference between “go search all of git yourself” and “just ask.”
- Actions, not just answers. The agent connects to services through MCP, so it can actually do things — with a human in the loop before anything runs.
- An agent that talks to other agents. Because teams had already built their own agents, I had us build an agent-to-agent (A2A) protocol: the IDX Agent recognizes when a request belongs to another team’s agent and hands off to it — so it’s a single entry point in front of the whole ecosystem, not a replacement for it.
Bootstrapping the evals
You can’t improve an agent you can’t measure. To build our evaluation set, I used Claude Code — connected to the relevant repos, services, and Slack support channels — to generate candidate questions and expected answers, then had each owning team validate them. What would normally take weeks of manual work took about a day of effort (an hour or two to draft, then ~30–60 minutes per team). That eval set became the backbone of our benchmarking.
Results
- A single conversational entry point over 300+ repos and dozens of tools — one place to learn, query, and act.
- Agent-to-agent orchestration, so the agent grows with the ecosystem instead of competing with it.
- An eval harness built in days, not weeks, giving us a real benchmark to improve against.
- A faster on-ramp for new hires and less context-switching for everyone. (Adoption metrics still maturing.)
What I learned
The hardest part of a platform agent isn’t the model — it’s the plumbing and the politics: keeping knowledge fresh automatically, and designing for a world where other teams keep shipping their own agents. Meeting that reality with an A2A protocol — rather than trying to own everything — is what made a single front door actually viable.